复杂网络综述2——现实世界中的网络
近些年来,大量的工作通过观察真实网络的特性试图对其建模,研究不同类型的网络具有重大意义。在这方面,Watts和Strogatz起了主要的推动作用,二人于1998年发表的论文《Collective dynamics of 'small-world' networks》被公认为是一项开创性的工作,它从不同角度研究网络结构特性。宽泛的看,现实世界中的网络可以分为四种——社交网络、信息网络、技术网络和生物网络。
- 社交网络
社交网络是由一些人或者一些群体和他们之间的一些联系和交互模式构成的网络。过去研究个体间的朋友关系、公司间的商业关系和家庭间的近亲婚姻关系都属于这种网络。在各类学科中,社会科学在研究真实世界网络方面有着悠久的历史,早期有记录的工作有:1934年J.L.Moreno研究在小群体内的朋友关系网络;1941年Davis等人做的“southern women”的研究;1939年Elton Mayo等人以工厂工人为研究对象,提出了Rapoport数学模型,成为第一个强调各种网络中(不仅仅在社交网路中)度分布的重要性的模型。

另外一些重要的实验,例如著名的由Milgram做的“小世界”实验,尽管在这些实验中并没有构建出真实的网络,但它们无一例外都揭示了具体的网络结构。通过在熟人网络中让参与者尽可能的将信件送达至一个特定的人,参与者需要指定最有可能认识该人的朋友,然后将信件转交给朋友,因此得出在熟人网络中路径长度的分布。实验中大多数信件都丢失了,但是大约有四分之一的信件仅仅通过六个人就成功送至目标。尽管在Milgram的论文中没有出现“six degrees of separation”这样的字眼,但是该实验被认为是六度分离理论的起源,该理论在1990年由Guare正式提出,而再早之前类似的研究要追溯到1979年Garfield的《It's a small world after all》。
传统的社交网络研究受限于数据不精确、假设带有主观性和样本数量小的问题。除了极少数像Milgram这样独创性的间接研究,数据采集大都是通过调查问卷的方式完成的,这种方法限制了网络的规模。此外,调查数据经常带有主观性,例如,不同的人可能对朋友的定义不同。尽管在消除这种差异性方面做出了很大的努力,但是不得不承认大多数研究中存在着大量不可控的误差,这类问题Marsden做出了总结。
这些问题的出现使得很多研究者转向其他的研究方法。一个丰富并且可靠的数据集是合作网络,在这种典型的“隶属网络”中,参与者在不同的群组内合作,组内之间的参与者有连边。一个典型的例子就是电影演员网络,如果两个演员共同出演了一部电影,那么就认为两人之间有一条连边;另外一个例子是公司董事网络,如果两个董事隶属同一个董事会,那么他俩之间就会有连边;还有像学术界的合作者网络,如果两位学者共同发表一篇或者多篇论文,那么他们之间就存在连边;还有一种叫“共现网络”,在这种网络中,个体间如果包含相同内容则二者间会有链接,这种情况多出现在网页或新闻报道之间。
另一个较为可靠的数据集是人们之间的通信网络。例如,可以构建一个网络,网络中两人的连边(有向)表示一封邮件从一个人发往另一个人。Aiello,Chung和Lu等人分析了一段时间内的电话网络,节点代表电话号码,连边代表从一次通话(一个电话号码到另外一个电话号码),尽管实验只进行了几天,这个网络也是巨大的——大约有5千万个节点。Ebel,Mielsch和Bornholdt在Kiel大学的5000个学生中重构了email网络,节点代表邮件地址,有向边代表从一个地址到另一个地址。Newman,Forrest和Balthrop等人对Email网络也做了深入研究。
- 信息网络
“信息网络”有时候也叫“知识网络”,学术论文之间的相互引用就是一个典型的信息网络。这些引用所形成的网络中,节点表示一篇文章,从A指向B的边表示A引用了B,引用网络的结构反映了蕴含在节点内的信息结构。引用网络是非周期的,因为一篇文章只能引用已经被发表的文章,而不是未发表的。所以,网络中不存在闭圈,即使存在,也很少。
引用网络作为科学研究中的对象,在数据集的丰富性和精确性方面有着极大的优势。对出版物进行定量研究最早要追溯到1926年由Alfred Lotka开创性的发现——Law of Scientific Productivity, 该发现表明,科学家发表的论文数服从power law分布,也即发表了k篇论文的科学家的数量为 人(
为常数)。事实上,该发现也适用于艺术和人文科学 。由于Eugene Garfield等人在文献计量学领域的工作推动了引用数据库的开放,第一个正式的有关引用模式的工作在1960年进行。Price在之前更早的一篇文章中讨论了引用网络,文章指出网络中的入度和出度都服从power law分布。从那之后,通过使用有史以来最好的引用数据库,出现了许多关于引用网络的研究。
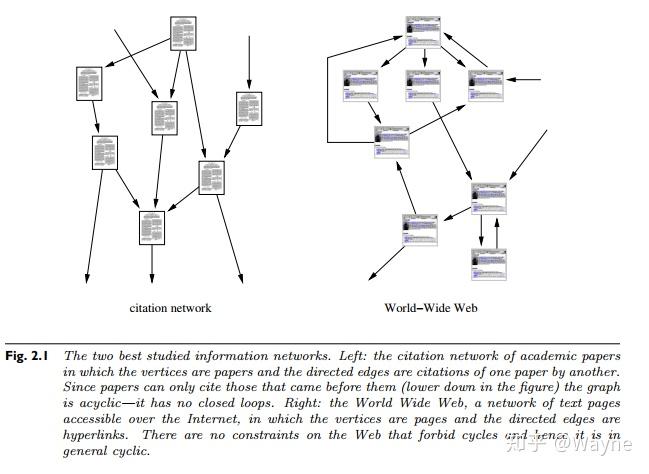
另一个十分重要的信息网络是万维网(World Wide Web),与引用网络不同的是,万维网是周期的,里面不存在对站点的自然排序,但是会包含闭圈。对于网页的研究早在20世纪90年代就开始了,Albert、Kleinberg和Broder等人做出了突出的贡献。
值得注意的是,数据是在网络上爬取的,通过超链接可以从一个网页跳转到另一个网页。网页只能通过指向它的链接被找到,一个网页有越多的链接指向它,就越可能被找到。这表明,网络中有着较小入度的网页的比例被低估了。这正好与引用网络形成对照,在引用网络中,一篇论文即使从未被引用过,也会出现在引用索引中(其实大多数论文从未被引用过)。
一些其他的信息网络则没有得到广泛研究。例如,Jaffe和Trajtenberg研究了美国专利引用网络,结果显示在一些方面与学术论文的引用网络相似。还有一些学者关注P2P网络,这是一种虚拟的网络,它可以在计算机用户间共享文件。Knuth等人研究在一个词库中,各个单词之间的关系,这种网络也可以看成是一个信息网络,词库的使用者在网络中浏览单词来找到想要的。然而,它也可以看做是一个代表语言结构的概念网络。
偏好网络是一个二分的信息网络,这种网络中包含两类节点,分别代表个体和他们各自喜好的客体,比如书籍或电影,个体和客体之间存在连边(边上的权重表示喜好程度)。由此衍生出的协同过滤算法和推荐系统可以预测个体的喜好,协同过滤算法在推荐商品和定向投放广告方面取得了巨大的成功。偏好网络还可以看做是社交网络,连边不仅仅连接个体和客体,还可以存在个体与个体之间,Kautz等人使用了这种算法。
- 技术网络
技术网络是用来分配一些商品或者资源的人工网络,比如电网。电网将高压电在三相传输线上跨越一个或者多个城市进行传输,Watts和Strogatz, Watts, Amaral等人对电网进行了统计研究。其他的一些分布式网络,比如航空网,公路网、铁路网、电话网络和运输网络也有一些研究。
另一个被广泛研究的网络是因特网,这里指的是由计算机通过物理连接形成的网络。因特网上的计算机数量巨大且千变万化,因此,网络结构只能在粗粒度上来衡量,要么看路由器的数量,要么看自治系统的数量。事实上,因特网上的物理连接并不容易被观察得到,因为基础设施大都由分散的组织来管理。因此,研究者们通过路由器之间的数据交换来重构网络,这里要用到一些网络技术,虽然不能保证重构的网络是完美的,但其基本结构保持不变。
然而这些技术网络都有一个有趣的特点——网络结构很大程度上由空间地理位置决定。电网,航空网,公路网,铁路网,这些网络中相互连接的节点大都既能满足某项功能,又能在地理位置上行得通,尽管现在还不是很清楚这些因素是如何相互作用的。
- 生物网络
大量的生物系统都可以用网络来表示,最经典的生物网络是代谢网络。Jeong, Fell和Wagner,Stelling等人对代谢网络做了大量的统计工作。
另外一个十分重要的生物网络是基因调控网络,基因的表达可以看做是转录并翻译蛋白质的过程,这种过程因为其他蛋白质的出现而表现出两种不同的行为——激活和抑制,因此,基因组本身就形成了一个switching网络,节点代表蛋白质,有向边代表一种蛋白质的产生对另一种蛋白质的依赖。基因调控网络事实上是第一个我们试图去建模的大规模动态网络。
另一个被大量研究的生物网络是食物链,顶点代表生物系统中的一个物种,有向边从A指向B表示A捕食B。构建完整的食物链是一项艰难的任务,对食草动物的食物链做了彻底研究的是Jordano,Bascompte和Olesen等人,他们统计了至少53种不同的网络。
神经网络是另一种生物网络,刻画真正的神经网络的拓扑结构是极其困难的,但是在一些小的例子中却可以实现,最有名的例子是重构线虫282个神经元网络。在对大脑神经网络结构的研究中,Sporns和Tononi,Edelman等人研究了大脑的功能区。
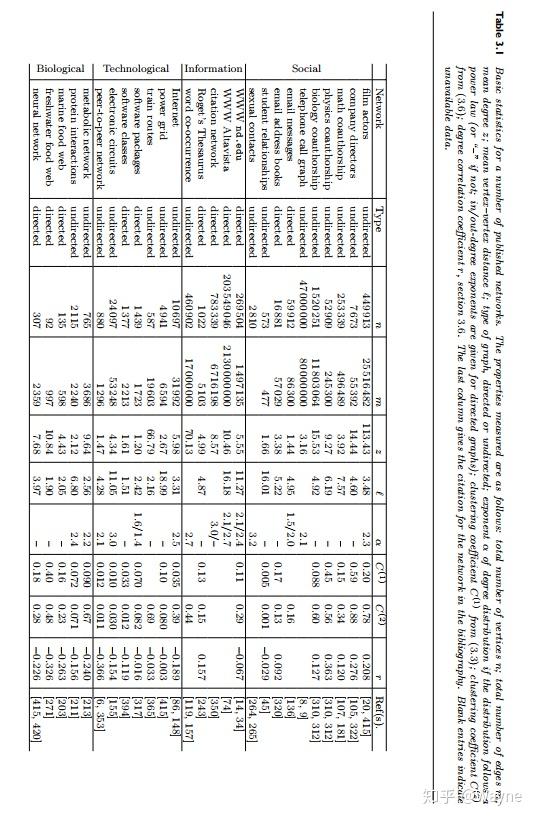
四种网络的一些例子: