
大规模神经网络优化:二阶优化器
在本节中,我们将学习一系列二阶优化器。首先我们会比较全面的了解与二阶优化器相关的基础概念。在充分理解这些概念的基础下,我们将很轻松的理解各类二阶优化器。(系列目录)
考虑函数的二阶泰勒展开
当上式取得最小值时,有 。牛顿法即使用更新:
,其中
为网络参数,黑塞阵
,这里我们简单考虑
可逆。在凸函数上对比梯度下降法收敛率
,当初值接近收敛值时,牛顿法有更快的收敛率
。
牛顿法计算黑塞阵()和矩阵求逆(朴素
,当
不可逆时需求解
)的计算复杂度高。
在前面的章节中,我们已经讨论过高斯-牛顿阵是黑塞阵很好的近似。记神经网络为 ,
为参数量。则
。其中
是函数
对
的黑塞阵(形状为
),
是
的雅可比矩阵(形状为
)。通过该方法可以计算雅克比矩阵避免对黑塞阵的计算,同时保证
是半正定的。

另一条思路是将 估计为
,
利用递推的方式从
更新。我们可以让
为对称正定阵等良好性质便于求得更新值
,使得
。
联想割线法(secant method)中对梯度的估计,我们有 ,注意到
,整理可得
。在该公式下,根据不同的假设可以得到不同的拟牛顿法。这包括 SR1 方法(symmetric rank-one,假设
秩为一),Sherman-Morrison 方法(SR1 基础上直接对逆进行递推),BFGS 方法(假设
秩为二),DFP 方法(BFGS 基础上直接对逆进行递推)。其中,BFGS 方法可以保证
正定,总时间复杂度为
,记
为
,
为
,更新公式为
然而 的还是难以接受。L-BFGS 通过储存最近的 k 个
,通过每次从初值开始,进行 k 次迭代用 IFQN 算法直接计算
,从而降低复杂度到
。但对于神经网络而言还是太大。
黑塞向量积 Hessian-vector-product 是关于 的一个基本操作。虽然优化中我们更关注
,而不是
(
是[
]的向量)。但该方法在分析神经网络曲面,以及凸函数的共轭梯度法中有应用(虽然在深度学习中梯度存在噪声,共轭梯度法不能保证方向的共轭性,难以应用)。
虽然计算 需要
的复杂度,计算
只需要
。在第一次反向传播获得梯度
后,将梯度和向量
做乘积得到的值
再次进行反向传播,就可以得到
。其原因在于
。这里
的数学含义是方向梯度
。PyTorch 中的实现为
F.hvp。
目前的深度学习框架往往都提供了高效的 vector-Jaccobian-product 和 Jaccobian-vector-product,例如 PyTorch 中的 F.vjp 和 F.jvp。为了计算高斯-牛顿阵与向量的乘积 Gauss-Newton-vector-product(),第一步可以先计算
。通过计算
雅克比矩阵与向量
的乘积(jvp),可得
。继而计算向量
与
雅克比矩阵的乘积(vjp),即可得到答案
。
利用 ,我们可以对黑塞阵的对角线元素进行估计。Hutchinson 方法是对实对称矩阵对角线元素的估计方法。令
,其中
是一个服从于高斯分布
的随机向量,则有
。
数学推导可参考该中文资料
在第一篇中我们已经定义过费雪信息矩阵(Fisher Information Matrix, FIM)。这里我们从神经网络的视角重新定义一次。一般而言,神经网络旨在建模一个分布(对于判别式神经网络,建模条件分布
),其中
是神经网络的参数。使用交叉熵损失与最大似然等价,目标为最大化
。定义评分函数
为对数似然函数的梯度(神经网络梯度的负数)。
评分函数有性质 。这里要格外注意一点,期望是在分布
下计算的,而不是在数据集上计算的。记数据分布为
,
与
之间存在差距,随着训练的进行不断减小(训练就是
对
的拟合)。故
不一定为零。类似的期望取值之后也要注意。
此时费雪信息阵可以有一个比较直观的定义:FIM 即评分函数(网络导数)的二阶矩。即。由于
,此时二阶矩就是评分函数的协方差。
在之前我们已经知道 FIM 与 Hessian 的关系,即 。但此黑塞阵不是在数据集上计算的。虽然当训练充分,网络拟合的分布接近实际分布时两者应该接近,但一般而言,
与实际的
的差距有多少呢?
这里我们借助[LLH'23+]中的推导分析判别式网络,证明其 FIM 就是该网络的高斯-牛顿阵,即 。首先,记网络输出为
。对
求导可得
。故在拟牛顿法开头提到的
与真实类别无关。其中
是一个对角阵,对角线上的元素为
。
由于 与真实类别无关,我们无需按照数据集进行采样,而是可以直接在网络输出的分布
上采样。如此
。由于
是
对
的雅克比矩阵,与真实标签无关,故
。
由于在神经网络中, 是
很好的近似,故
也是
很好的近似。因此,可以用
代替
进行优化,即
。但
仍然需要
的储存开销,同时还有按网络分布采样计算梯度,以及计算
的计算开销。
FIM 阵除了可以看作是对 Hessian 的估计以外, 本身还具有一个直观的数据解释。单步优化中,我们希望更新方向使损失最小:
其中 是一个空间度量,衡量两个参数的距离。在(最速)梯度下降方法中使用了欧氏距离,可得
,即负梯度方向。当更新量为
时,学习率
。
然而我们的目标是最大化似然函数,参数的改变导致似然函数 在函数空间的改变。故我们希望使用一个度量
衡量函数空间的距离,此时我们可以选择 KL 散度(虽然其不是一个严格的距离),即
。用泰勒展开近似到二阶项可得
,进一步可得
的方向为
。该项被称作自然梯度,沿该方向的梯度下降被称作自然梯度下降。
我们计算当 KL 散度的更新量为定值 时,学习率
应该为多少。令
,解得
。我们有:
记 为自然梯度更新方向,又有:
其中 被称作牛顿减小项(Newton decrement,
是
的近似),通过计算可以得到牛顿下降法单步更新损失的最大更新值为
。而
为牛顿更新步长在黑塞阵下的范数(一些论文中也叫做方向锐度 directional sharpness)。故条件 KL 散度变化为定值,也可以改写为。更新值
。
回忆梯度下降的中更新项为 ,如果在分母上保留
,那么该梯度下降为归一化梯度下降法(normalized gradient descent)。而带学习率项的自然梯度下降与归一化梯度下降有相同的形式,或许可以称作“归一化自然梯度下降”或“归一化牛顿下降”。
上述各类算法中,我们都再梯度前引入了一个逆矩阵得到形如 的更新方向。我们可以称
为预条件子(preconditioner)。目前对优化器的设计,主要是对预条件子的设计。当预条件子为对角阵时,
可以很方便的获得。此时也可以看作在每个维度上进行自适应更新(adaptive)
,比如 Adam 类的优化器以及 Sophia 优化器。预条件子可能能起到一下作用:1.降低方差 2.对高条件数问题鲁棒 3.提供高阶(曲率)信息。
给定列向量 ,其外积可以定义为
。其中前一项是两个向量的乘积,后一项是两个向量的 Kronecker 积。Kroneckor 积的定义如下:
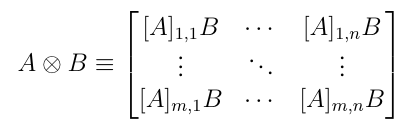
在神经网络中,参数具有结构性质(第层的参数记为
)。在计算 FIM 阵时,我们把所有的参数平等对待。定义
算符将 Tensor
转为为向量(
flatten)。Kronecker 积可以方便的表示外积向量化的结果,即 。
Kronecker 积有一系列良好的性质:
- 对于正定矩阵
,
K-FAC 算法是自然梯度下降的一种近似实现。定义 MLP 网络中第层为
(为简化不考虑 bias),其中
为激活函数。梯度
。K-FAC 算法使用三个近似以高效的实现自然梯度下降。
近似一:作者利用服从数据集分布的数据来计算二阶矩,进而近似计算 FIM 阵,即 。这里
是从数据集中采样的数据。但是只有当网络分布接近真实分布时两者才能近似。实际上一个好的估计是经验 FIM 阵:
。然而由于梯度计算是批量进行的,我们只能得到一个批量样本中作为一个整体的
。作者用该近似避免了额外的采样计算开销。
近似二:将每层的参数作为整体,可以把 FIM 阵分块。。又根据链式法则中有
。结合 Kronecker 积的性质 1 我们有
。
如果我们维护 的移动平均作为估计,则需要
的储存空间。K-FAC 利用近似
从而只需维护两个向量的移动平均,即
的储存空间。[MG20]主要根据实验说明其效果不错。下图中左图是
,中间是
的近似,右图是两者的差。

近似三:在前向和反向传播中,和
都是已有的值,故
阵已经可以计算了。为了方便计算
的逆,作者进一步对
阵的结构做了两种假设,分别是块对角(block-diagnoal)矩阵和块三对角矩阵(block-tridiagonal)。这里我们只讨论前者。在该假设下,我们只关心
,即层内的相关性(假设不同层间弱相关)。根据 Kronecker 积的性质二,我们有
。根据性质三,可得自然梯度
。
学习率调整:通过上式计算出自然梯度后,我们还要对自然梯度的学习率进行修正。与之前推导自然梯度下降学习率类似,当 KL 散度的近似值 大于阈值
时([GM16]中选择 0.3)将其裁剪。即学习率
。如此可以限制每次更新时 KL 变化的幅度。其中,
的计算可以通过”黑塞向量积“一节的技术快速计算。作者实际每个几个批量计算一次,进一步降低均摊开销。
其它实现细节:在该方法的一个实现中,作者基于 K-FAC 添加动量时,动量应用在自然梯度上。权重衰减也应该发生在函数空间,故应使用 作为预条件子,实际中仍然使用参数空间的衰减
。计算正定矩阵
的逆时,可以通过特征值分解
,其中
是正交矩阵,
是对角阵,其对角线上的元素为特征值。故
。为了获取前向传播中的
和反向传播中的
,可以通过 pytorch 的 hook 功能快捷实现。

缺点:虽然通过三个近似,可以一定程度高效的实现自然梯度下降,然而 K-FAC 算法具有不少缺点。
- 通过带噪声的梯度信息近似曲率信息会使高阶信息估计不准确。即使是在大批量(低噪声)的情况下,[MMY+19]通过实验表面 K-FAC 效果不如 SGD。
- 三个近似一定程度也损失了精度。
- 对于不同的网络结构(如卷积等)需要重新推导,实现较为复杂。
受到 K-FAC 的启发,[GRB21]将拟牛顿法 (L-)BFGS 推广到神经网络上。与 K-FAC 类似,作者在 Kronecker 积以及块对角阵假设的基础下设计了 K-BFGS 算法。由于使用不广,这里不再赘述。
Adaptive 类算法(Adagrad[DHS11], Adam[KB14]等)中的自适应学习率,可以看作是使用了对角阵的预条件子。在该篇内容中,我们还会从别的视角探究这类算法。本篇则从曲率信息的角度进行探究,为了方便这里不讨论权重衰减、动量修正等技术。记梯度为 ,预条件子为
,更新量为
(梯度下降即
),
。
Adagrad 算法在一位参数上的自适应学习率为 。而在原始论文中,实际上 Adagrad 的原始形式是
。这里我们采取与原论文不同的分析方法。注意到 K-FAC 中的近似一,即用数据分布近似计算 FIM 阵。我们同样可以将 Adagrad 看作是近似 FIM 阵的预条件子加上随时间的梯度衰减,即
。这里预条件子使用了
而非
,这与曲率之间能否建立联系呢?
在归一化自然梯度下降中,我们通过设定学习率 让每步的更新幅度相等。在学习率与动量一章中,我们讨论过高条件数对优化的不利影响。考虑
的特征值
对应的特征向量
,如果我们希望对每个特征向量进行伸缩变换,使
相等,从而让不同特征值对应的更新幅度相等。令
,解得
。记梯度
在
上的分量为
,此时
。对比
,我们发现特征值进行了开根,故我们可以选择
作为预条件子以满足
的选择。由此可见,Adagrad 算法(以及不包括
学习率衰减的 Adam 算法)可以看作是”特征值归一化的自然梯度下降“。
Adagrad 中继续将 限制为对角阵,这样可以减小
的储存空间、求逆以及开方的复杂度。由于
的对角线构成的矩阵为
,其中
是第
个参数的导数。故
。
从曲率的角度看,Adaptive 类算法实际上是利用数据分布近似的对角 FIM 阵(牛顿阵)下的特征值归一化的自然梯度下降(或牛顿梯度下降)。
Shampoo 算法[GKS18]是对 Adagrad 更新量的近似计算。记 Adagrad 的更新量为 是对
的近似计算。
矩阵是一个[nxn]的矩阵,储存、求逆、求方根开销都很大。如果使用对角近似,我们可以看成在每个位子上使用了[1x1]的矩阵,大量减小了开销,然而丢失了大量信息。那能否在这两者之间取得一个平衡呢?
一个简单的思路是类似 K-FAC 一样使用块对角矩阵,即只考虑每层参数内的相关性。对于第 层参数
,
为该层导数,
是
重整(reshape)成与
形状相同的矩阵。则更新公式为
。但这样做需要维护一个
矩阵以及对其求逆和求方根,仍然是不小的开销。
Shampoo 算法将 进行近似,这里我们只做直观理解,理论证明可以参考原论文。对于形如[
]的二维矩阵
,令
([
]),
[
],更新为
。其中
,与 Adagrad 中的次数相同。如此一来,我们只需要维护
和
的矩阵,以及对其求逆和求方根。这样大大减小了计算开销。
对于一般的张量 有形状[
],总大小为
。维护
个矩阵,每个矩阵是
。这里
是
重整成[
]形状的矩阵。如此一来,
有形状[
]。为了计算最后的更新量,将
轮流 重整成[
]形状的矩阵,计算
,再将其 reshape 成原状。此时总次数为
,与 Adagrad 中的次数相同。维护的矩阵大小为
,与直积计算整层的
相比减小了计算开销。

[YGS+21]放弃了 K-FAC 和 Adagrad 中的近似一,并估计为对角矩阵。其通过上文提到的 Hutchinson 方法估计 的对角阵
,维护梯度动量
和对角阵动量
。使用与 Adam 一致的更新方式,即
,在每个维度上更新方向为
。
在此基础上,AdaHessian 还用平均池化将 的值进行平滑,从而使训练更稳定。
Sophia 算法[LLH'23]在 AdaHessian 算法的基础上进行了改进。首先,其通过真实的 函数对
进行了估计。根据“费雪信息阵与牛顿法”一节的内容,计算
时损失函数应使用按照网络输出概率采样的真实标签,即
注意到实际训练中我们无法得到单个样本的 ,只能得到一个批量的
。不过幸好由于
,我们有
由于该操作需要额外的一次反向传播,作者通过每隔 步采样一次的方式进行近似,并做动量更新,从而降低了计算开销。
此外,Sophia 没有使用 Adam 中 -1/2 次的“特征值归一化”,而是直接使用自然梯度下降,即 。为了应对自然梯度下降训练的不稳定性,作者对更新值进行裁剪,使其不超过给定的阈值。
[DHS11]Adaptive Subgradient Methods for Online Learning and Stochastic Optimization
[KB14]Adam: A Method for Stochastic Optimization
[MG15]Optimizing Neural Networks with Kronecker-factored Approximate Curvature
[GM16]A Kronecker-factored approximate Fisher matrix
for convolution layers
[GKS18]Shampoo: Preconditioned Stochastic Tensor Optimization
[MMY+19]Inefficiency of K-FAC for Large Batch Size Training
[GRB21]Practical Quasi-Newton Methods for Training Deep Neural Networks
[YGS+21]AdaHessian: An Adaptive Second Order Optimizer for Machine Learning
[LLH'23+]Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training

